


概述
Kafka是一种高吞吐量的分布式流处理平台,由LinkedIn开发,现在由Apache基金会维护。Kafka因其高效的数据处理能力而被广泛应用于大数据场景中。本文将探讨Kafka高效的原因,包括其架构设计、性能优化和生态系统支持等方面。
分布式架构
Kafka的核心是其分布式架构。它允许数据在多个节点之间高效地分发和处理。以下是分布式架构带来的几个关键优势:
水平扩展:Kafka可以轻松地通过增加更多的节点来扩展其容量,这使得它能够处理大规模的数据流。
高可用性:通过副本机制,Kafka确保了数据的持久性和服务的可用性。即使某个节点发生故障,数据也不会丢失,并且服务可以无缝切换到其他节点。
负载均衡:Kafka通过负载均衡机制将数据均匀地分布在不同的节点上,从而避免了单个节点的性能瓶颈。
主题(Topics)和分区(Partitions)
Kafka使用主题来组织数据流,每个主题可以包含多个分区。以下是主题和分区带来的高效原因:
并行处理:由于每个分区都是独立的数据流,消费者可以并行地从不同的分区读取数据,从而提高了处理速度。
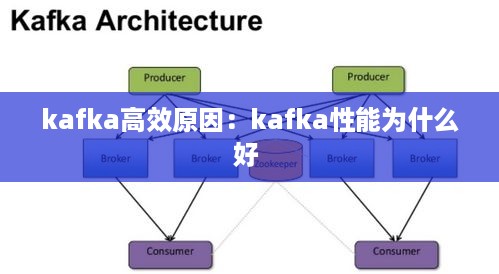
灵活的读写操作:分区允许灵活的读写操作,消费者可以根据需要订阅特定的分区,而不必处理整个主题的数据。
易于管理:分区使得数据管理更加灵活,例如可以通过分区来控制数据的保留策略和备份策略。
消息的持久化和压缩
Kafka通过将消息持久化到磁盘来实现数据的持久性。以下是这一机制带来的高效原因:
持久性保证:通过将消息写入磁盘,Kafka确保了即使系统故障,数据也不会丢失。
高吞吐量:Kafka支持多种压缩算法,如GZIP和Snappy,这些算法可以显著减少磁盘I/O和带宽消耗,从而提高吞吐量。
高效的消息传递机制
Kafka的消息传递机制设计得非常高效,以下是几个关键点:
零拷贝技术:Kafka使用零拷贝技术来减少消息在传输过程中的数据复制,从而提高性能。
异步I/O:Kafka使用异步I/O来处理消息的写入和读取,这减少了阻塞操作,提高了系统的吞吐量。
缓冲区管理:Kafka通过智能的缓冲区管理来优化内存使用,减少了内存的碎片化,提高了性能。
生态系统和工具支持
Kafka拥有强大的生态系统和工具支持,这使得它在数据处理领域具有很高的效率:
连接器(Connectors):Kafka Connect允许用户轻松地将Kafka与其他数据源和系统集成。
流处理(Streams):Kafka Streams是一个轻量级的流处理库,允许用户在Kafka上构建实时应用程序。
流计算(Kafka Streams API):Kafka Streams API提供了丰富的操作符来处理流数据,使得开发更加高效。
结论
综上所述,Kafka之所以高效,主要得益于其分布式架构、主题和分区设计、消息的持久化和压缩机制、高效的消息传递机制以及强大的生态系统支持。这些特性使得Kafka成为处理大规模数据流的首选工具,广泛应用于实时数据处理、事件源、流分析等领域。
转载请注明来自山东高考日语培训,日本留学,枣庄日语培训机构,本文标题:《kafka高效原因:kafka性能为什么好 》








 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...